We are pleased to share the initial checkpoint of our reasoning foundation large language model as an open-source resource. This checkpoint is intended to help evaluate our team's data production pipeline across various domains, including mathematics, programming, logic, safety, and others. Its goal is to provide a solid starting point for developing a robust policy for the subsequent reinforcement learning process.
We are hopeful that applying our reinforcement learning algorithms, supported by our carefully designed infrastructure, will lead to meaningful improvements in the model’s reasoning capabilities across various domains. At the heart of the project is our data production pipeline, which we believe plays a crucial role in enabling general reasoning capabilities. We also believe that the reasoning capability induced by the data production pipeline can address a range of real-world industrial scenarios with increasing precision and reliability.
Based on our observations during the production of \(\pi_0\), we have identified quality and diversity as critical factors for fostering high-quality, long Chain-of-Thought (CoT) reasoning capabilities. This insight aligns closely with conclusions drawn from the general alignment process of large language models. By meticulously designing self-verification and backtracking mechanisms to ensure process correctness in data generation, we have developed datasets that effectively induce robust long-context reasoning across diverse domains. This approach demonstrates superior performance compared to state-of-the-art o1-lile models with similar objectives, highlighting the potential of our data production pipeline in advancing reasoning capabilities.
To ensure a fair comparison of our developed data production pipeline, we conducted supervised fine-tuning on the Qwen2.5-32B-Instruct model using the data generated by our pipeline. The performance of this fine-tuned model is compared against the Qwen2.5-32B-QwQ model, recognized as the most advanced o1-like open-source model. Additionally, we incorporated the baseline results from the o1 model and Qwen2.5-32B-Instruct to provide a comprehensive evaluation.

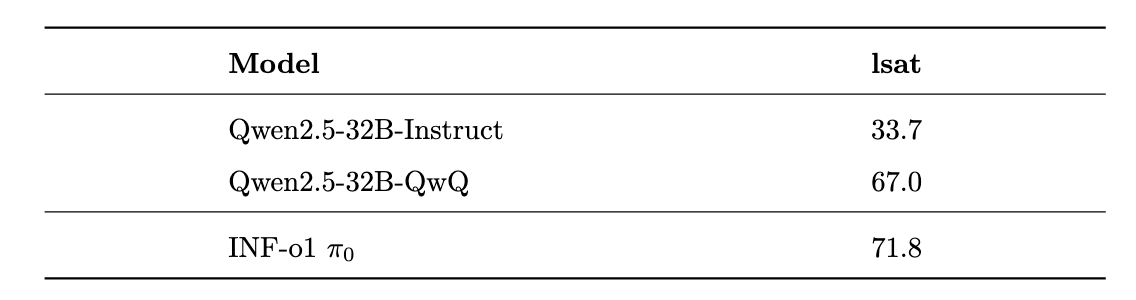
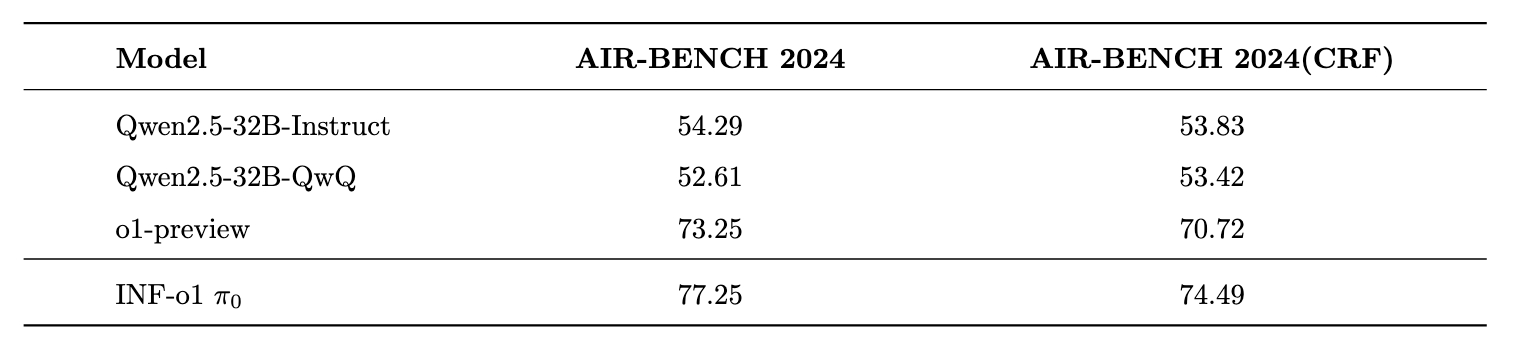
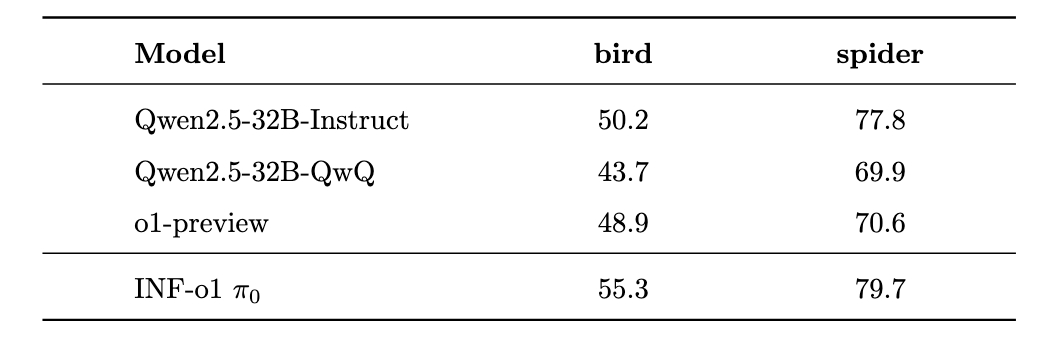
We evaluated our \(\pi_0\) model on a set of custom benchmarks, including tasks in math, SQL, safety, and logical reasoning, and compared its performance against the Qwen2.5-32B-QwQ model. The results indicate that \(\pi_0\) achieves comparable performance on most benchmarks and outperforms Qwen2.5-32B-QwQ in logical reasoning, SQL, and safety tasks, which are particularly critical for industrial applications. All evaluations were conducted using our internal framework and may differ from results reported on other open-source platforms. Furthermore, the results presented here were obtained using a greedy decoding strategy, without leveraging advanced techniques such as Best-of-N or pass@K.
Our \( \pi_0 \) serves as the foundation for ensuring that our data generation pipeline effectively leverages the long reasoning capabilities of large language models. Looking ahead, we plan to use \( \pi_0 \) as the initial policy checkpoint for reinforcement learning training. Through this process, we aim to significantly enhance the generalization of reasoning capabilities, particularly for tasks in the financial and medical domains, which are critical for both academic research and industrial applications.
INF-o1 Team
Wei Chu • Yinghui Xu • Yuan Qi
Chao Qu - Team Leader • Chao Wang - Infrastructure • Cheng Peng - Data Pipeline (Logical) • Dakuan Lu - Data Pipeline (Science) • Haozhe Wang - Data Pipeline (Math) & RL • Hongqing Hu - Infrastructure • Jianming Feng - Data Pipeline (Safety) • Jiaran Hao - Data Pipeline (SQL) & Infrastructure • Kelang Tian - Infrastructure • Minghao Yang - Data Pipeline (Math) • Quanbin Wang - Data Pipeline (Safety) • J.K. Liu - Data Pipeline (SQL) • Tianchu Yao - Data Pipeline & Alignment • Weidi Xu - Data Pipeline (Logical) • Xiaoyu Tan - Data Pipeline & Alignment • Yihan Songliu - Infrastructure
Chao Qu: quchao_tequila@inftech.ai
Xiaoyu Tan: yulin.txy@inftech.ai
@misc{inftech_pi_zero2024,
author = {INF-o1 Team},
title = {INF-o1 (\(\pi_0\)): Initiating the Journey to the Infinity of LLM Reasoning},
year = {2024},
url = {https://inftech-pi-zero.github.io/},
note = {Accessed: 2024-12-31}
}